Rajagopal is a highly skilled Data Engineer with advanced expertise in Python programming, relational databases, and designing scalable data pipelines. His expertise includes data modeling and transforming large, complex datasets (both structured and unstructured) using distributed systems like Apache Spark and Flink. Rajagopal is adept at query optimization and building efficient data solutions in cloud environments like AWS. He is a collaborative problem-solver focused on contributing to feature development and ensuring data integrity within fast-paced, AI-driven teams.
Spearheaded the setup of core processes and best practices for the Trust Data Science team, including data governance, reliability improvements, and foundational dataset development.
Developed a real-time metrics dashboard by building a Flink-based streaming service to process live event data and generate platform health metrics, significantly improving incident response.
Led an org-wide initiative to overhaul data logging practices, enabling self-serve access to key metrics and reducing dependency on the DS team.
Developed a centralized Supertable for the Trust Review Operations team as part of a data democratization initiative, saving 200+ man-hours annually.
Built and maintained a central warehouse that powers foundational datasets, ensuring high data quality and freshness within defined SLAs for 50+ Tier1/Tier2 datasets.
Designed a scalable analytics query gateway service for the Customer Obsession domain at Uber, enabling flexible metric querying across multiple data sources and reducing onboarding time.
Led a data governance project to enhance data management practices by establishing clear ownership for datasets and implementing Time to Live (TTL) policies.
Built anomaly detection systems that proactively detected business issues, saving ~$500K.
Built a data validation utility to compare datasets, which saved ~50 man-hours monthly.
Created access controls for all datasets based on a least privilege access control principle, helping in preventing accidental data loss, and recovery would take ~1 month.
Worked closely with ML teams to build features needed for ML models like R&A issuance, which has a budget of $1 billion annually.
Designed ETL pipelines that are GDPR compliant and adhering to security practices.
Owned 100+ Tier 1/Tier 2 datasets, responsible for their SLAs and performance optimization.
Developed a real-time audience size estimation that reduced processing time from 2 hours to 5 minutes with a small error margin.
Co-developed an ETL pipeline in Apache Spark for rule-based campaigns to improve efficiency for larger scales.
Co-developed an engineering pipeline to use Machine Learning models for campaigns, impacting revenue by $10M.
Developed an application that analyzes log messages and alerts when an application goes down.
Improved the existing algorithm by 3 times and disk space by 20 times.
Worked in the Walmart Ad Exchange (WMX) team, building data pipelines for audience targeting and campaign measurement.
Co-implemented a propensity segment pipeline as an ML-based audience targeter worth millions of dollars for Walmart and got an approximate estimate of audience size in real time using data sketches.
Migrated data between clusters and changed logic and code when upstream data source/infrastructure changed.
Implemented clustering and graph algorithm techniques to find human traffickers and reported to DARPA.
Worked on DARPA-funded projects to detect online fraudulent activities in various domains like human trafficking, selling illegal weapons, and counterfeit electronics.
Gathered information from different websites and the entity linking them and finally visualized the results.
Developed the front end of a web application to manage APIs.
Built the client side of a web application using SmartGWT, Java, and API management, where API service providers can create proxy projects with different requirements like customized quota, data output, added security functionality, and modify user permissions.
JavaSmartGWTObject-oriented Programming (OOP)
Web Applications
APIsAPI Management
Flipkart
Intern
2013 - 2013
Bangalore, India
Developed a sales dashboard showing all the analytics of what products are selling fast with different filters like category, location, and time.
Developed a VBScript module that sends a daily email update to topline management about the sales.
Developed an inventory planning dashboard that gives an estimate of required inventory based on previous sales and present pace of selling.
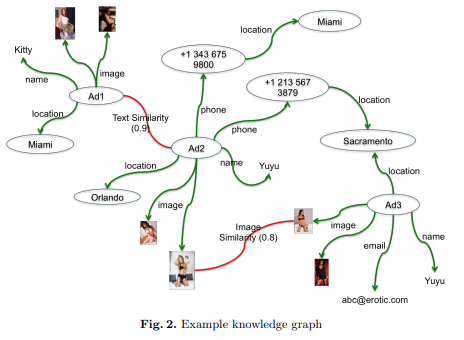
This implementation was part of a human trafficking project. Grouped the ads that look syntactically similar together so we know that these are posted by the same guy most likely. Modelled the data as a graph using Apache Spark GraphX and found people who operate in groups and big guys using PageRank and connected components. Got very good results and work got featured in Forbes. Tech stack: Spark, GraphX, Scala, Clustering. Link (pdf): http://iswc2015.semanticweb.org/sites/iswc2015.semanticweb.org/files/93670175.pdf
This was a Kaggle project. Predicted whether an ad will be clicked or not using a feature set. Compared the results using different classifiers such as Decision Tree, Random Forest, and SVM. Used PCA algorithm for feature selection. Plotted the results of different classifiers on ROC Curve and found that Random Forest was the best classifier. Tech stack: Python, Machine Learning.
Dataset used Audioscrobbler-data, recommended artists to user using Latent Factor Model and got mean AUC for user as 0.96 (1 is best). Implemented user-user and item-item collaborative recommendation system on an IMDB movie dataset. Tech stack: Python, Spark MLlib, Scala.